
Scientific understanding, document engineering, artificial intelligence and open science.

Projects
Document engineering
GROBID is an Open Source tool for parsing and extracting structured information from technical and scientific documents in raw format like PDF.The large majority of the scholar documents are only available in PDF (more than 90% of the papers prior to 2000) which is not adapted to text mining processing and corpus analysis. Even when a publisher XML format is available, the level of structuring might not be sufficient and uniform, so further processing and harmonization are often necessary.GROBID has been developed to address these issues in a reliable, fast and scalable manner thanks to machine learning techniques – cascaded sequence labeling models (CRF and RNN). This tool is the first building block of a text mining infrastructure, it is actively maintained and continuously improved.Grobid was created by Patrice Lopez, Luca Foppiano (now, as ScienciaLAB) has been involved in the development and maintenance since 2016.


Metadata extraction
GROBID extracts the bibliographic metadata information (title, authors, affiliations, abstracts, etc.) of a scientific document in PDF with an accuracy between 80-95%, in order of seconds.Structured citation extraction
GROBID extracts bibliographical references with an average accuracy between 70-90% per reference and provides standard bibliographical formats for further integration in a text mining or digital library system.
Document body structuring
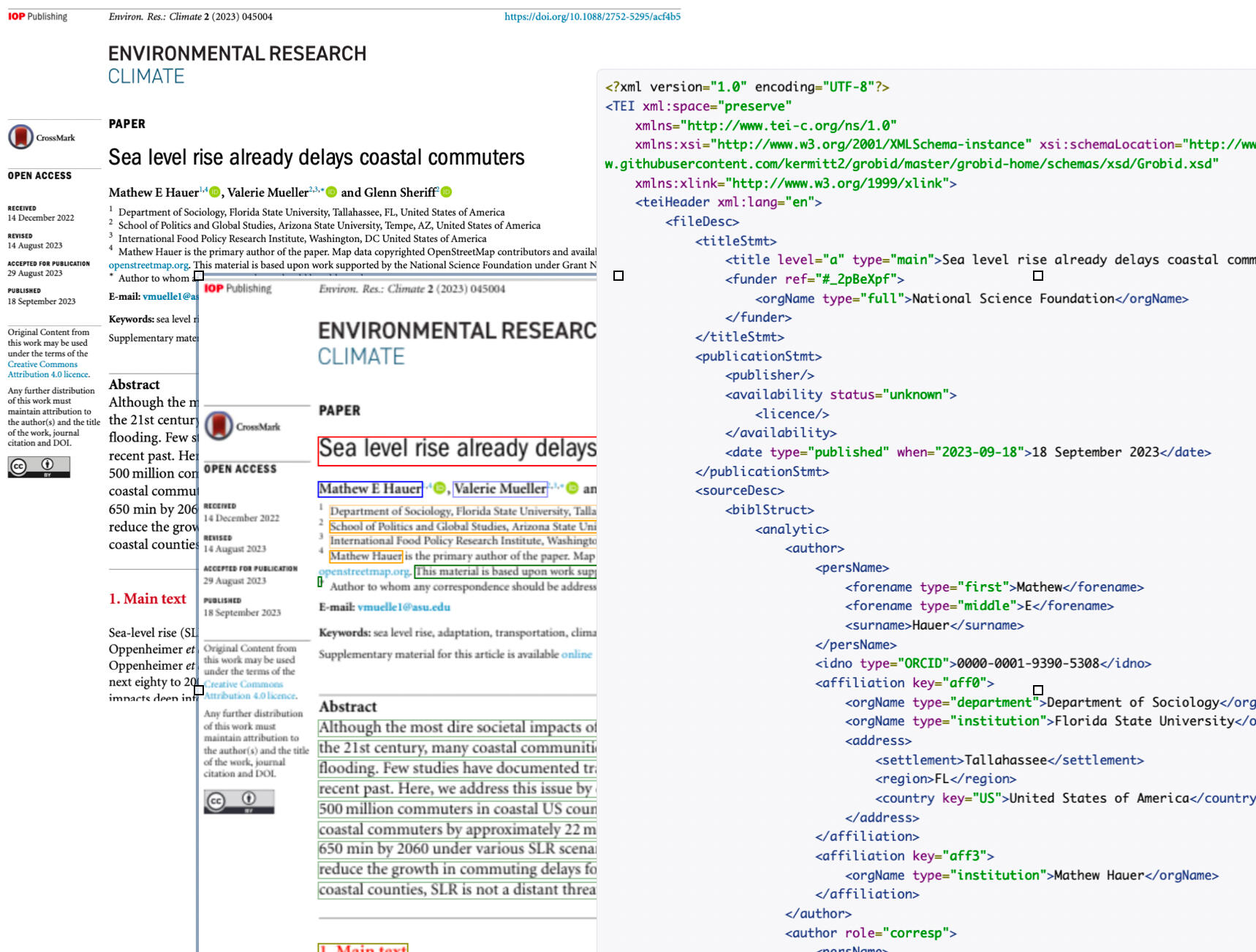
GROBID can extract, normalize and structure the body of a PDF document in XML-TEI. The explicit recognition of paragraphs, section titles, citation call-out and contexts, figures, tables, formula, foot notes, etc. make possible a valid usage of modern text mining techniques.
Converting the full-text articles the publishers provided in the PDF into a machine-readable text format is still a challenging task.
GROBID is one of the rare tool addressing this bottleneck, providing complete full text structures with state-of-the-art and continuously improving accuracy, in a scalable implementation.
PDF layout and structure alignment
The structures extracted from GROBID are synchronized with the original PDF layout through coordinates. This makes possible to dynamically enrich the original PDF documents with clickable, in context, annotations without modifying the original file.Structure vision is a demo application illustrating how Grobid-extracted annotations can be handled on a PDF document.
Identification of scientific entities
Recognition and normalisation of physical quantities and measurements
The expressions of physical quantities and measurement are fundamental in STEM and are characterised by a particular nomenclature. Identifying and normalizing these expressions into SI base units enable a vast range of applications, in particular to search quantities in document collections, to apply numerical data mining techniques, or to extract automatically knowledge about experimental conditions.
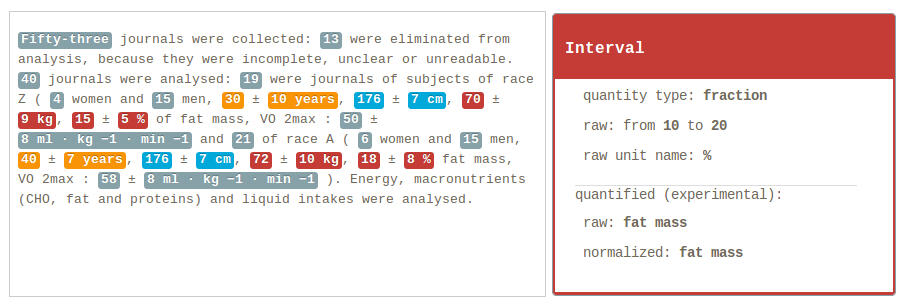
grobid-quantities recognizes in textual documents (text, PDF, XML) expressions of measurements (e.g. pressure, temperature, etc.), then parses, normalizes them, and finally converts these measurements into SI units. For English, the tool supports more than 120 base units and expressions of atomic, interval and lists of values. In addition, grobid-quantities tries to identify and attached to the measurements the “quantified” substance or objects.

Based on grobid, grobid-quantities exploits all the document structuring capabilities offered by Grobid, including the ability to decorate PDF documents with the extracted information.


Automatic extraction of materials mentions and propertiesIn the scope of materials science there is a need for extracting datasets of experimental data from scientific articles.
Combining a specialised model for the identification of materials mentions, and grobid-quantities, material-mentions (initially called grobid-superconductors, and limited to superconductors materials) allow the recognition of materials expressions including chemical formula, samples, variable replacements, stochiometric formulas.
We combine the extraction of materials mentions with the collection of the desired properties required in the task.

Using grobid-superconductors, we built a pipeline of data ingestion and curation called SuperCon2, a staging area for SuperCon (Superconductors database built by the National Institute for Materials Science, in Japan).
The tool was able to collect a database of 40,324 materials and properties records from 37,700 papers.
The material (or sample) information is represented by name, chemical formula, and material class, and is characterized by shape, doping, substitution variables for components, and substrate as adjoined information. The properties include the Tc superconducting critical temperature and, when available, applied pressure with the Tc measurement method. This automatic database become part of a more sophisticated data cycle composed by a comprehensive curation workflow, aiming to produce high quality experimental data collected from scientific literature.


This curation workflow allows both automatic and manual operations, the former contains ‘anomaly detection’ that scans new data identifying outliers, and a ‘training data collector’ mechanism that collects training data examples based on manual corrections.Such training data collection policy is effective in improving the machine-learning models with a reduced number of examples.
For manual operations, the user interface is developed to increase efficiency during manual correction by providing fast context switching through an enhanced PDF document viewer.

Large Language Models
LLMs (Large Language Models) have improved how computers understand and generate natural language, making communication more efficient.Retrieval Augmented Generation (RAG) enhances this by allowing the model to access dynamic information for more accurate and up-to-date responses.AI Agents automate complex tasks with minimal human input, and are leveraged to replace or reduce human interaction in recursive tasks.

Document Insight Q/A a is a library that implements a RAG (Retrieval Augmented Generation) system that integrates document engineering (Grobid) and the scientific entities extraction.
Different to most of the projects, we focus on scientific articles using Grobid to extract structured text and coordinates.
Grobid provides faster and cleaner results than most solution based on classical PDF to Text converters.

The application provide a Q/A interface as a chat. The user selects the model and uploads a PDF document. The document is processed by Grobid and stored in a vector database.
When the user ask a question, the LLM select the most relevant context and uses it to answer the question. The user may verify the answers by looking at the PDF viewer which display an enriched PDF documents where the context chunks used to answer the question are highlighted in order of importance (warm colors are considered more relevant with the question, while cold colors are less relevant).

The PDF viewer is a Streamlit component developed initially at NIMS (National Institute for Materials Science), and continued as an open source project.Beside the more than 100 projects using this component, we developed
Structure vision as a demonstration on how to use the annotations generated by Grobid or any other application for text extraction from PDF documents.

Research
We are committed in collaborating with research institutes and supporting open source projects.Our goal is to foster innovation and contribute to the advancement of technology by providing resources and expertise to the community.
ScienciaLAB is currently working on collaborative project with:
- DFKI: Deutsches Forschungszentrum für
Künstliche Intelligenz GmbH
- INRIA: Institut national de recherche en sciences et technologies du numérique
- Helmholtz-Zentrum Hereon - „HElmholtz“, „REsilienz“ „InnovatiON“
- Eurac - Institute for Applied Linguistics
ScienciaLAB aims in creating open-source solutions that drive innovation, collaboration, and global progress.


People
ScienciaLAB strive to aggregate collaborators all over the world, to provide a all-round range of skills for R&D projects and research initiatives. We provide a fully-remote and flexible package.







About
Our goal is to improve the understanding of scientific knowledge through machine learning, and artificial intelligence.
We provide and maintain open source tools and R&D services to assist scientists to manage the growing volume of available scientific and technical information, spanning from conventional scholarly publications to experimental and specialized datasets.
Our emphasis is on scholarly text mining, the extraction of scientific knowledge, and knowledge engineering. We develop and sustain Open Source software for the scientific community's benefit and offer consulting and R&D services related to scientific information.
ScienciaLAB serves as a bridge connecting researchers, companies, and institutes. We advocate for a fully decentralized work environment, and believe that cultural diversity significantly enhances our lifestyle and overall well-being.
Company information
Name: GRUTA ENTRANÇADA
Company status: UNIPESSOAL LDAEmail: [email protected]
Address: Rua Homes do Andor 2A #129, 8100-670, Loulé, PortugalVAT number: PT518489868

Contact
Open source projects
Following a list of further open source projects complementary to our goals:- streamlit-pdf-viewer: A component for visualisinz and annotating PDF documents in Streamlit.
- biblio-glutton: A blazing-fast bibliographic data lookup for scientific publications
- to be continued.